Background
Artificial intelligence is not new. It has been part of our personal and work lives for a long time (autocorrect, facial recognition, satnav, etc.) and large language models like ChatGPT have been a big topic in education since version 3.5 was released in late November, 2022. Large language models (LLMs) are trained on enormous amounts of data in order to recognize the patterns of and connections between words, and then produce text based on the probabilities of which word is most likely to come next. One thing that LLMs don’t do, however, is computation; however, the most recent Open AI release, GPT-4, seems to have made strides in standardized tests in many STEM areas and GPT-4 now has a plug-in for Wolfram Alpha, which does do computation.
Andrew Roberts (Math Dept) and Susan Bonham (EdTech) did some testing to see how ChatGPT (3.5), GPT-4, and GPT-4 with the Wolfram plugin would handle some questions from Langara’s math courses.
Test Details
Full test results are available. (accessible version of the problems and full details of the “chats” and subsequent discussion for each AI response are available at the link)
The following questions were tested:
Problem 1: (supplied by Langara mathematics instructor Vijay Singh)

Problem 2: (Precalculus)

Problem 3: (Calculus I)

Problem 4: (Calculus II)

Discussion
Responses from current versions of ChatGPT are not reliable enough to be accepted uncritically.
ChatGPT needs to be approached as a tool and careful proof-reading of responses is needed to check for errors in computation or reasoning. Errors may be blatant and readily apparent, or subtle and hard to spot without close reading and a solid understanding of the concepts.
Perhaps the biggest danger for a student learning a subject is in the “plausibility” of many responses even when they are incorrect. ChatGPT will present its responses with full confidence in their correctness, whether this is justified or not.
When errors or lack of clarity is noticed in a response, further prompting needs to be used to correct and refine the initial response. This requires a certain amount of base knowledge on the part of the user in order to guide ChatGPT to the correct solution.
Algebraic computations cannot be trusted as ChatGPT does not “know” the rules of algebra but is simply appending steps based on a probabilistic machine-learning model that references the material on which it was trained. The quality of the answers will depend on the quality of the content on which ChatGPT was trained. There is no way for us to know exactly what training material ChatGPT is referencing when generating its responses. The average quality of solutions sourced online should give us pause.
Below is one especially concerning example of an error encountered during our testing sessions:
In the response to the optimization problem (Problem 3), GPT-3.5 attempts to differentiate the volume function:
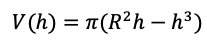
However, the derivative is computed as:
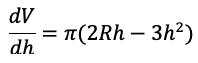
We see that it has incorrectly differentiated the first term with respect to R while correctly differentiating the second term with respect to h.
It is the plausibility of the above solution (despite the bad error) that is dangerous for a student who may take the ChatGPT response at face value.
Access to the Wolfram plugin in GPT-4 should mean that algebraic computations that occur within requests sent to Wolfram can be trusted. But the issues of errors in reasoning and interpretation still exist between requests sent to Wolfram.
Concluding Thought
It will be important for us educate our students about the dangers involved in using this tool uncritically while acknowledging the potential benefits if used correctly.
Want to Learn More?
EdTech and TCDC run workshops on various AI topics. You can request a bespoke AI workshop tailored to your department or check out the EdTech and TCDC workshop offerings. For all other questions, please contact edtech@langara.ca
